
L'industrialisation chez Emakina
Chez Emakina, nous adressons de nombreux projets en parallèle au quotidien. Ces derniers peuvent durer de quelques mois à plusieurs années. Certains sont même en constante évolution depuis plus d’une décennie.
S’il devait y avoir un point commun entre tous ces projets, ce serait certainement notre volonté de servir le plus efficacement possible nos clients. Pour être à la hauteur de cette ambition, il est fondamental d’optimiser le fonctionnement de l’organisation. C’est cette démarche d’amélioration continue que nous nommons industrialisation.
Dans cet article, nous allons voir ensemble comment nous nous sommes structurés au travers de trois thématiques : spécialisation, standardisation, automatisation.
Spécialisation
Avant même de parler de standardisation ou même d’automatisation, il convient de partir de l’élément principal autour duquel tout gravite : l’humain. Peu importe la qualité des outils, une équipe se doit d’être organisée pour être performante.
Nous avons mis en place un cadre permettant à nos équipes de développement de progresser sur le chemin de l’expertise.
Pour commencer, le métier de Web Developer a été scindé en deux métiers qui sont à la fois distincts et complémentaires : Back-end Developer et Front-end Developer.
Pourquoi ce choix ? Parce que nous préférons accompagner nos développeurs sur le chemin de l’expertise. Cette décision a d’ailleurs été motivée à la fois par la volonté de nos équipes et par la nature même de nos projets.
Un peu plus récemment et toujours dans la même logique, des équipes spécialisées sur un nombre restreint de technologies ont été constituées. Cette réorganisation permet d’obtenir plus facilement ce que l’on pourrait qualifier de Solution Specialist, ainsi que des équipes qui ont l’habitude de travailler ensemble.
Il ne faut pas non plus s’enfermer dans son seul domaine d’expertise. Pour être en mesure de collaborer le plus efficacement possible, il faut savoir sortir de sa zone de confort afin d’appréhender les spécificités d’autres technologies, voire d’autres métiers. Kenneth Rubin aborde ce concept sous le nom de “T-Shaped Skills” dans son livre Essential Scrum (source).
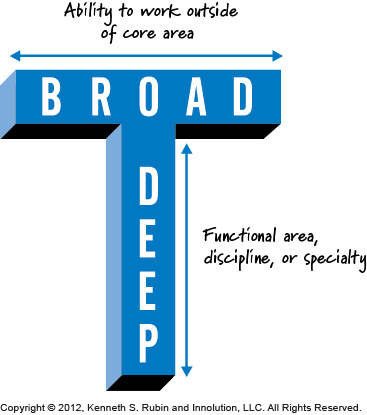
De notre côté, il s’agit d’une caractéristique que nous affectionnons particulièrement et que nos experts techniques partagent tous.
Standardisation
Une erreur des plus fréquentes est de vouloir automatiser sans d’abord commencer par rationaliser les usages. En faisant cela, on se disperse et on perd un temps considérable. Alors que nos actions auront bien plus d’impact si l’on commence par réunir tout le monde autour d’un même standard, et que l’on bâtit ensuite un référentiel commun.
Il ne peut y avoir d’automatisation efficace sans qu’il n’y ait eu de standardisation au préalable.
Environnements locaux
Une des premières choses que nous avons standardisées fut la gestion de nos environnements locaux. Historiquement, chaque développeur était responsable de l’installation des projets sur sa machine. Cette façon de faire avait trois inconvénients majeurs.
- L’absence de cadre faisait que les environnements locaux n’étaient pas systématiquement en adéquation avec les environnements de production. Il n’était pas rare d’avoir de mauvaises surprises lors des déploiements, c’était l’époque du fameux “ça marchait sur ma machine”.
- La durée d’installation des projets était directement liée aux connaissances de la personne en termes d’administration système. Tous les développeurs n’ayant pas forcément une sensibilité DevOps, l’exercice pouvait s’avérer complexe en fonction de l’architecture souhaitée.
- La cohabitation de divers environnements n’était pas possible. Or, nous travaillons sur de nombreux projets en parallèle à l’échelle de l’entreprise, et il n’est pas rare de devoir basculer d’un projet à l’autre.
Docker a été la réponse idéale à ces problématiques : réplication de configurations standards et isolation pour éviter les éventuels conflits. Chaque technologie dispose maintenant d’un environnement standard, et une seule commande suffit pour démarrer tous les services nécessaires au bon fonctionnement d’un projet. Il n’y a plus besoin de connaître l’intégralité de la stack technique pour se mettre à développer.
Golden Rules
Lorsque l’on travaille en équipe, encore plus avec de multiples équipes, il est important de partager des règles communes. Nous avons créé notre propre ensemble de règles que tout le monde, peu importe l’ancienneté ou les responsabilités, doit suivre. Ce sont nos “Golden Rules”.
Ces règles sont au nombre de 20 et sont réparties en 4 niveaux d’importance. Sans rentrer trop dans les détails, elles vont du respect de notre workflow Git et de la bonne utilisation des gestionnaires de dépendances, jusqu’à l’incitation à la contribution open source.
Gestion du code source
En plus des règles évoquées précédemment, nous avons aussi standardisé la gestion du code source de nos projets. Nous étions à la recherche d’un workflow Git qui se devait d’être le plus intuitif possible, tout en offrant une grande liberté en termes de déploiements.
Nous sommes arrivés sur un consensus qui est qu’une seule branche doit être considérée comme permanente. Tous les développements, nouvelles fonctionnalités ou correctifs, partent de cette branche et sont ensuite fusionnés dans celle-ci. Pour garantir l’intégrité de la branche principale, trois critères conditionnent l’intégration de nouveaux changements.
- Les changements effectués doivent être validés par nos tests automatisés, que nous verrons plus en détail dans la thématique suivante.
- Plusieurs développeurs doivent les approuver, d’un point de vue technique via la revue de code.
- Le product owner doit lui aussi les approuver, d’un point de vue fonctionnel via Jira.
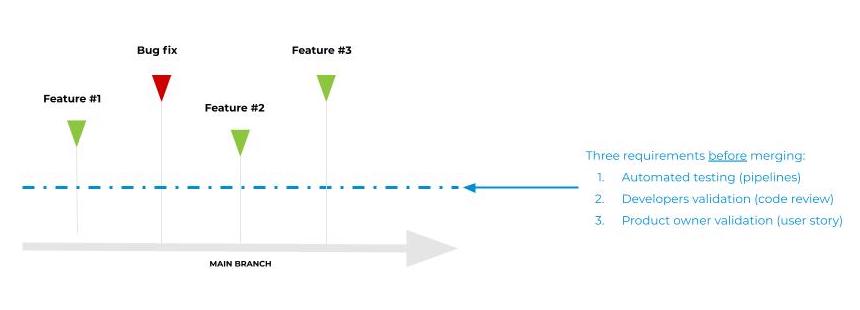
Si cette méthodologie peut sembler être un frein au développement au premier abord, il s’agit pourtant de la raison pour laquelle nous sommes capables de déployer en continu. À chaque fois qu’un nouveau changement est intégré, il peut être déployé en production, étant donné que la branche principale est toujours considérée comme stable.
Revue de code
Personne n’est infaillible, ainsi il est indispensable que le code que l’on produit soit relu par une tierce personne. En effet, plus un problème est détecté tôt, moins il est coûteux de le corriger. Pour que cet exercice soit rigoureux, nous avons établi quelques règles élémentaires.
- Tout le monde peut participer, ce n’est pas limité aux seuls membres de l’équipe projet.
- Un minimum de 2 approbations est demandé, peu importe l’ancienneté ou l’expérience de la personne qui soumet les changements.
- Les approbations provenant de l’auteur de la merge request, ou de ses co-auteurs, ne sont pas comptabilisées.
Au delà du fait que ce processus limite grandement le risque d’introduire de nouvelles régressions, c’est aussi un véritable vecteur de partage de connaissances qui ne se limite pas à l’équipe projet. Il n’est pas rare de voir s’ouvrir des discussions dans l’objectif de trouver la solution technique la plus adaptée pour répondre à une problématique business.
Pour que cette méthodologie fonctionne, tous les participants doivent être convaincus du bien-fondé de la démarche. Elle a porté ses fruits chez nous, car tout le monde a joué le jeu.
Environnements distants
Le déploiement de nouveaux changements est toujours un moment critique dans la vie d’un projet, et souvent une opération redoutée par les développeurs. Cette crainte est directement liée au nombre d’opérations manuelles requises, mais aussi amplifiée par les potentielles spécificités propres aux projets ou technologies.
Là encore, nous avons recherché un consensus qui allie simplicité et fiabilité.
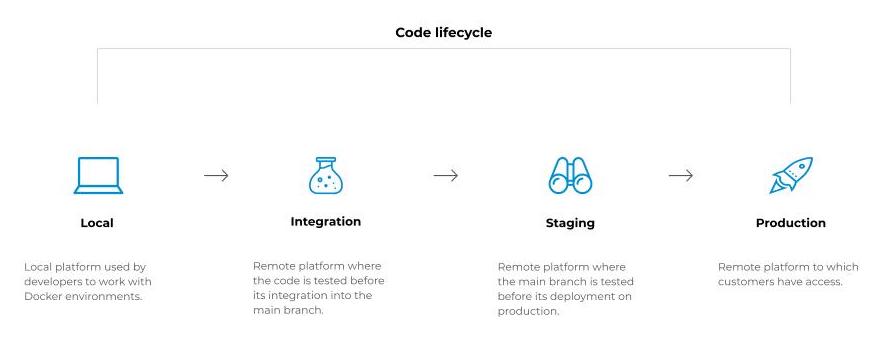
- Nous utilisons Docker sur nos machines de développement, car chaque application que nous développons nécessite une configuration spécifique pour fonctionner dans des conditions optimales. Nous voulons être sûrs que ce que nous testons en local sera ce que nous aurons une fois le code déployé.
- Lorsque le code est finalisé en local, il est soumis pour validation technique en ouvrant une merge request. Cette action permet le déploiement sur la plateforme integration, où toutes les merge requests ouvertes sont déployées pour être validées par le product owner. À ce moment, le code n’est pas encore fusionné dans la branche principale.
- Lorsque la validation est terminée et que le code est fusionné dans la branche principale, il peut être déployé sur la plateforme staging. Il s’agit d’une plateforme où il est possible de faire des retours avant le déploiement en production. C’est pourquoi une deuxième validation du product owner est demandée avant d’aller plus loin.
- Lorsque le code est déployé et validé sur la plateforme de staging, le déploiement en production peut être fait.
Chacun de ces déploiements est identifié par un tag Git spécifique, sous le format
vX.Y.Z, qui suit le versionnement sémantique. Par convention, nous utilisons la version0.1.0lors de l’initialisation du projet et la version1.0.0lorsque le site est en ligne.
Automatisation
Sur la base de nos standards, nous avons commencé à automatiser certains éléments de notre quotidien. Il fallait toutefois éviter de tomber dans le piège qui consiste à automatiser tout et n’importe quoi. Les automatisations qui ont le plus d’impact et qui requièrent le moins d’effort doivent être adressées en priorité. Si vous avez du mal à prioriser vos travaux, vous pouvez vous appuyer sur des méthodologies comme MoSCoW ou RICE par exemple.
Tout ce qui mérite d’être automatisé doit l’être, c’est le chemin le plus court vers la productivité.
Tests automatisés
Tous nos développements sont évalués par des tests automatisés basés sur des outils étant des références sur le marché. Cette automatisation permet d’offrir à nos équipes un avis quasi instantané sur la qualité du code produit, mais elle ne remplace pas la revue de code. Elle permet notamment de diagnostiquer tous les problèmes relatifs aux standards de développement pour que les humains se concentrent sur le fond plutôt que sur la forme.
- Pour la partie front-end : eslint, stylelint, audits de sécurité des dépendances JavaScript avec npm ou Yarn.
- Pour la partie back-end : phpcpd, phpcsfixer, phpstan, psalm, audit de sécurité des dépendances PHP avec local-php-security-checker.
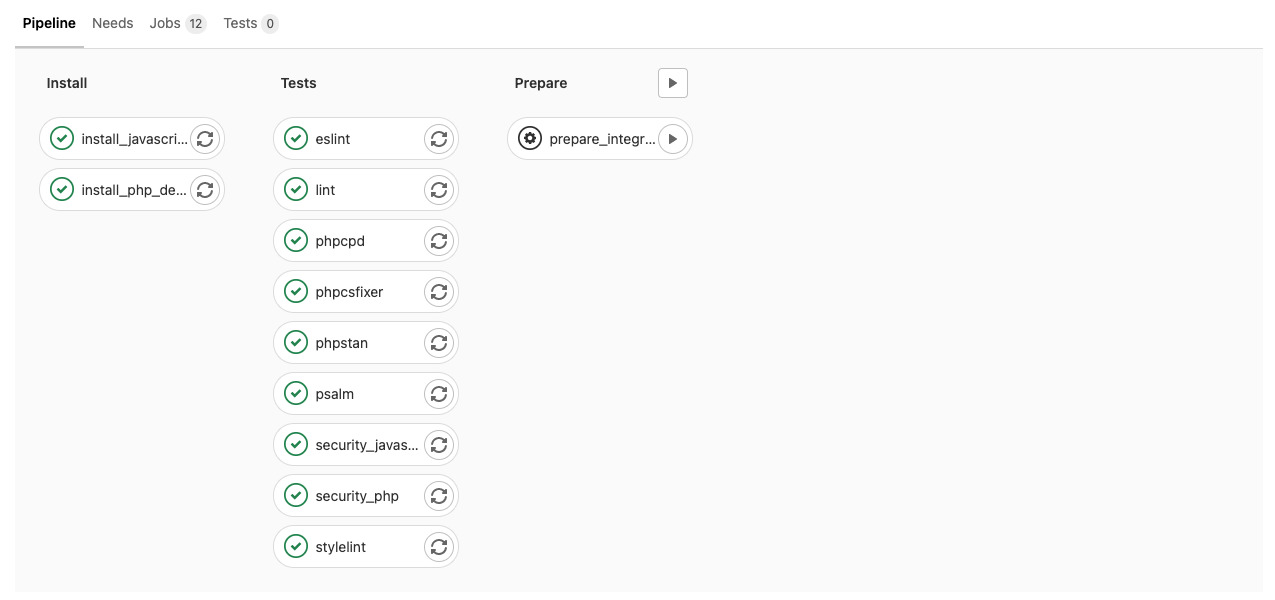
La plupart du temps, la revue de code ne démarre qu’après le succès des tests. Un test qui échoue implique de devoir corriger quelque chose, et donc de revoir les changements apportés.
Déploiements automatisés
Le déploiement du code source se doit d’être le plus simple possible. Quelqu’un qui n’est pas à l’aise avec cette étape risque de vite se retrouver dans une situation de dépendance, ce qui impactera directement sa faculté à faire valider son travail.
En revanche, plus le processus de déploiement est accessible, moins il est redouté par l’équipe et plus il est facile de multiplier les déploiements sereinement. Cette multiplication engendre un cercle vertueux : plus on déploie, moins le contenu des déploiements est important, plus les développeurs seront confiants lors des déploiements.
C’est d’ailleurs un prérequis avant la mise en place d’une politique de déploiement continu. Et c’est pour cette raison que nous avons fait en sorte que nos déploiements ne se résument qu’à (littéralement) un clic sur un bouton.
Une notification de post-déploiement est aussi envoyée automatiquement dans une conversation commune à toute l’équipe projet (pas que les développeurs). Celle-ci permet d’identifier en un coup d’oeil les fonctionnalités ou correctifs qui peuvent être testés, et de faciliter la communication avec nos clients.

Monitoring de l’obsolescence
Les technologies du web évoluent très rapidement. Les projets que nous développons se doivent de suivre cette tendance pour ne pas devenir obsolètes. Nous devons donc continuellement mettre à jour les dépendances de nos projets et migrer vers de nouvelles versions.
Nous avons actuellement la possibilité de faire un audit en temps réel des versions de PHP utilisées au sein de nos projets. Cette interface est disponible à tous nos collaborateurs, et en plus de la version de PHP utilisée, affiche aussi la date de sortie et la date de fin du support. Nos collaborateurs avec un profil moins technique sont alors en mesure de discuter de ces échéances avec nos clients, pour prévoir les migrations bien avant les échéances annoncées.
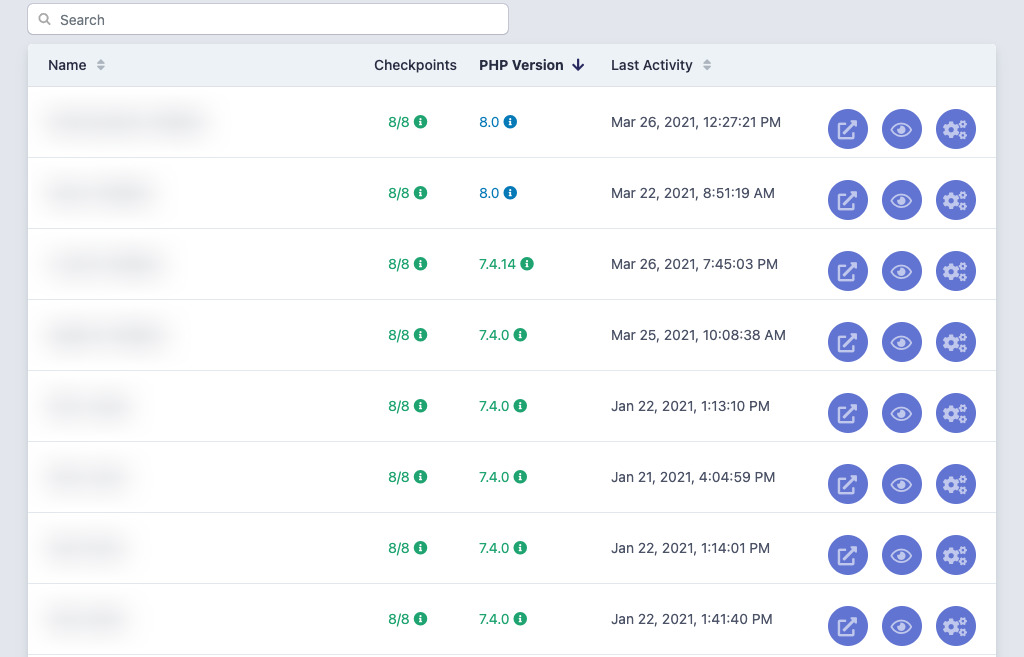
Dans un futur proche, nous comptons ajouter d’autres informations comme la version de la solution technique utilisée (e.g. Symfony) et son statut (maintenue, dépréciée, abandonnée).
Conclusion
Je tenais à partager à travers ces quelques lignes un aperçu du chemin que nous avons parcouru ces dernières années. Si certains points ont été abordés très rapidement, nous aurons l’occasion de rentrer plus dans les détails dans de prochains articles.
Par ailleurs, beaucoup de choses ont déjà été accomplies, mais nous n’en avons pas terminé et nous poursuivons toujours cette démarche d’amélioration continue. De nombreux sujets méritent encore d’être partagés. À très bientôt !

Alexandre Jardin Alexandre développe des applications Magento et Symfony depuis plus de dix ans. Il accompagne nos équipes sur les questions relatives à l'architecture ou aux performances, sans perdre de vue son autre mission : l'industrialisation.